Appiumは、WebDriverプロトコルに準拠したサーバー実装であり、モバイルアプリ自動化のもっともメジャーな手段です。Appiumで、アプリの画面をinspectionするときには、 Get Page Source コマンドによってページソースを取得します。また、要素に対してXPathを用いてアクセスするときなども、このページソースが参照されます。
ウェブ自動化のページソース
“Get Page Source”コマンドのWebDriverプロトコルにおける説明は、“The Get Page Source command returns a string serialization of the DOM of the current browsing context active document”となっており、これは、ブラウザ自動化の文脈では、単に document.documentElement.outerHTML の実行を意味します。つまり、画面のHTML表現です。
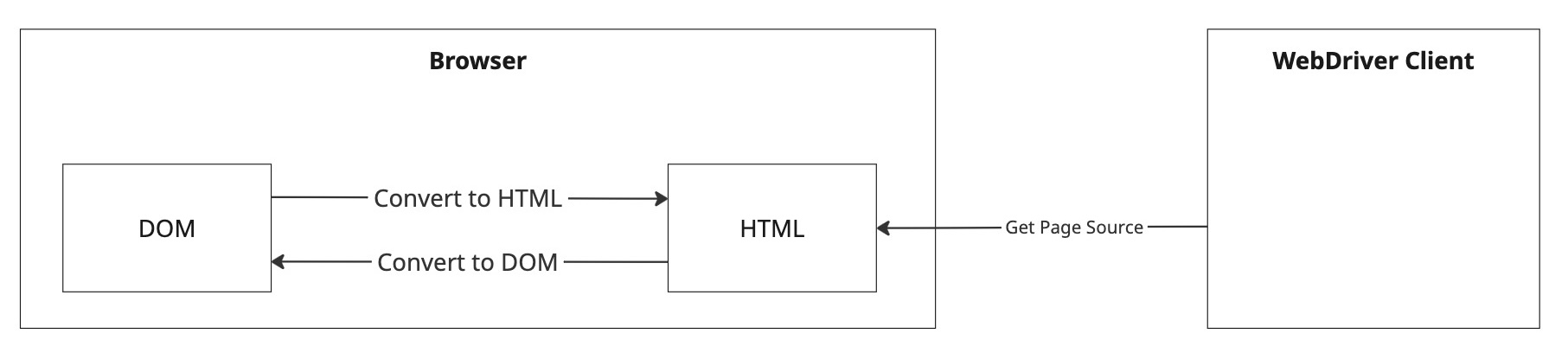
ブラウザの自動化においてDOMとHTMLは相互に変換可能
DOMがブラウザにおける画面の内部表現であることと、HTMLによってDOMを完全に再現できることを考えれば、ページソースは、現在画面上に表示されているもののソースコードといって差し支えないと思います。言いかえると、ブラウザ環境において、DOM/HTMLはプログラミングのための完璧なインターフェースです。非常に明解ですね。ただし、あくまでブラウザ自動化の文脈においては、なのですが…。
モバイル自動化のページソース
ひるがえって、モバイル自動化におけるページソースとは何なのかを見てみましょう。まず、注意しなければならないのは、Appiumにおいて、プロトコルこそ共通であるものの、利用可能なパラメータや挙動は、プラットフォームによってまったく異なります。DOMのようなプラットーム非依存に参照できる標準の内部表現もありません。DOMがプログラミングのためのインターフェースであるという意味で、それに相当する内部表現は、iOSでは、 UIView、Androidでは、 View となります。しかし、Appiumの”Get Page Source”で得られるものは、それらの”a string serialization”であることはたしかですが、ブラウザにおけるそれとはだいぶ様相が異なります。1
Appiumにおいては、内部表現へのアクセスは、 XCUIAutomation や UI Automator といった、テストフレームワークを通じて行われます。そして、それらのフレームワークでは、UIViewやViewといった内部表現に直接アクセスできるわけではなく、 XCUIElement や UIObject2 といった自動化のためのある種のプロキシを通じて対象のオブジェクトを操作します。ページソース取得時には、これらの自動化用オブジェクトが、 appium-webdriveragent (iOS)や appium-uiautomator2-server (Android)のような、デバイス内に常駐するサーバープロセスによって、XML表現にシリアライズされます。このシリアライズは、Appiumが独自に定義している処理です。一連の変換課程は、DOMに対するHTMLとは異なり、いかなる意味においても元のオブジェクトの復元を意図したものではありません。これらの変換は一方向です。ソースという言葉は、ふつう、なにかの「元となるもの」という意味ですが、Appiumにおけるページソースは、ソースではなく、内部表現のいくつかの側面を切り取った射影にすぎません。

モバイルの自動化において内部表現からとXMLへの変換は一方向
この本質的な仕組みの違いは、自動化において実際に影響を及ぼします。まず、これまで説明したように内部表現からXMLへの変換を通じて、かなりの情報が落ちてしまっています。画面上、あるいは内部モデルに存在するすべての情報に必ずしもアクセスできるわけではありません。また、その変換プロセスもウェブのようにきちんと定義されているわけではありません。たとえば、iOSであれば、デフォルトで50以上のネストレベルにある要素は取得できません。ページソースにどのような要素を含めるかについては、ある程度設定で変更できはするものの、自分の用途に合わせてどう最適化するか取捨選択する必要があります。また、どのようなツリーが生成されるかは、対象OSのバージョンやAppiumのバージョンに強く依存しますので、例え自動化対象のアプリ自体が同一だったとしても、常に一貫したツリーが得られる保証はありません。
そしてパフォーマンスにも問題があります。本質的にただの outerHTML であるウェブのページソース取得が極めて軽量であるのと対照的に、モバイルのページソース取得は、要素がidle状態になるまで待つなど、けっこう複雑な処理をしたりしています。結果的に十秒以上かかったりすることもざらで、ある程度以上要素の多い画面構成になると、そもそも取得がまったくできなくなったりします。
このようにモバイル自動化におけるページソースというのは、ウェブにおけるそれとはだいぶ異なった性質を持つのですが、実務的にはこれに頼らざるを得ないこともあるため、騙し騙し使っていくことになります。
サンプルコード
以下のコードで、ネストが深くなったときに要素が落ちる様子と、ページソースが大きくなったときにタイムアウトする様子を確認できます。
まとめ
- モバイル自動化におけるページソースは、ウェブのページソースと本質的に違う
- モバイルのページソースは、実際にはソースではない(一方向の変換)
- モバイルのページソースに含まれる情報は完全ではない
- モバイルのページソースは不安定(プラットフォームやAppiumのバージョンに依存する)
- モバイルのページソース取得は非常に遅い(ときには不可能)
- iOSでは、”mobile: source”という、より柔軟なコマンドも利用可能だが、本質は同じ ↩