はじめに
すこし前に、Chromeの開発をされているをやられている方のこんなスライドが回覧されてきた。
で、それを見てすこしひっかかったのが 15ページ のところ。 スレッドとプロセスの比較だけど、スレッドについて、このような言及がある。
そのぶんプロセスより軽い(メモリ使用量、コンテキストスイッチ)
あれ、コンテキストスイッチの時間って、プロセスとスレッドで違うんだっけ…。
ぼくはアプリケーションプログラマなので低レイヤーのことは詳しくないのだけど、 プロセスもスレッドも、スケジューラーから見ると同じタスクという抽象であるみたいな話をどこかで聞いたことがあって、 コンテキストスイッチの時間にも違いはないのかと、なんとなく思い込んでいた。
これを実際に検証する方法はないだろうか。 コンテキストスイッチにかかる時間を測る方法を検索してみたら、このようなStack Overflowの回答があった。
ふむふむ、これはおもしろい。ちょっとこの方法でプロセスとスレッドでコンテキストスイッチの時間が実際に違うのか検証してみたい。
コンテキストスイッチとは
現代のOSでは、限られたCPUの個数よりも多くのプログラムを同時に実行しているように見せかけるための、 マルチタスク という仕組みがある。
マルチタスク環境では、一つのCPU上に、次から次へと異なるプログラムを載せかえて実行する。
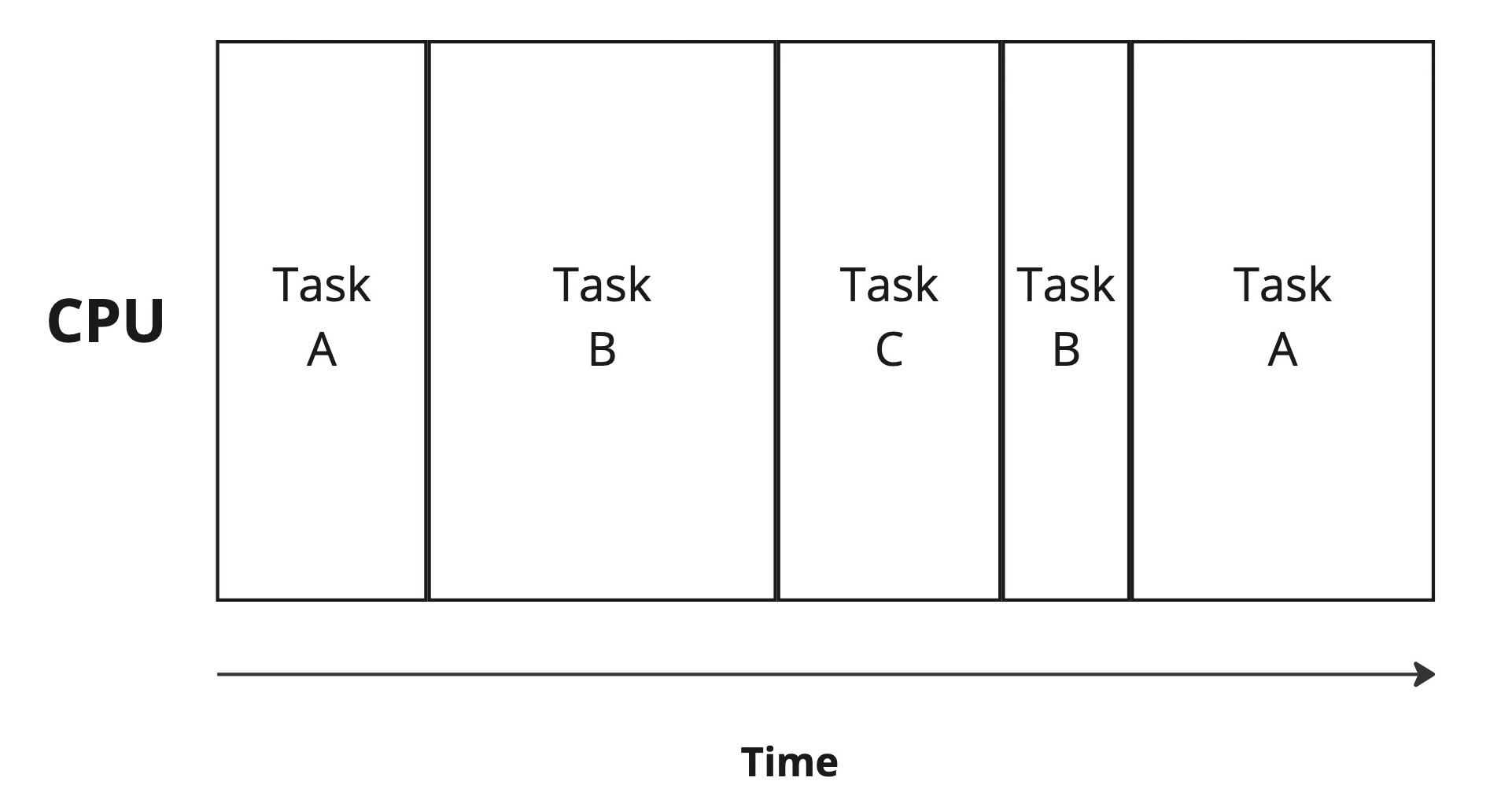
CPUとタスク。タスクはCPU上で次々と切り替わりながら実行される
このプログラムの載せかえのことを コンテキストスイッチ と呼ぶ。レジスタの状態などを退避・復元する必要があるため、コンテキストスイッチには、それなりの時間がかかる。
マルチタスク処理を実現するときに、アプリケーションプログラマが使える選択肢は何種類かある。 実行環境によっては、軽量スレッドと言われるようなアプリケーション(VM)レベルで実現されているマルチタスクの機構を利用できる、あるいはそれしか利用できない場合もある。けれど、多くの言語で利用できる、OSレベルで提供されるマルチタスクの手段は、プロセスとスレッドだ。プロセスとスレッドの最も大きな違いは、プロセスは独立したメモリ空間を持つが、スレッドはメモリ空間を共有するということ。
Unixプログラミング環境では、プロセスによるマルチタスクにはfork API、スレッドによるマルチタスクにはpthread APIを使う。
実験1: パイプを使って計測する
先のStack Overflowの回答で示されているアイデアは単純だけど興味深い。
タスクは、readのようなブロッキングI/Oと呼ばれるAPI1が呼ばれると、十分なデータが読める状態になるなど再度の実行が可能となるまで、CPUを他のタスクに明け渡す。2
回答で示されたコードでは、パイプからのreadでブロックが発生し、読み込めるデータもないために以降の行に遷移することができない。次いで、writeでデータが書き込まれることで、パイプの他端にデータが到達し、readのブロックが解除されることが期待される。つまり、writeが待機中のタスクを起こすための手段として使われている。これは、Unixプログラミングで、タスク間での同期を実現するときに、実際に使われることがある便利なテクニックでもある。
write前に取得したタイムスタンプをパイプで送ってから、read側でもタイムスタンプを取得し差分を取ることで、コンテキストスイッチにかった時間を計測しようというアイデアが、Stack Overflowの回答だ。なかなか賢い。 これを、プロセスとスレッドでそれぞれ実行し、計測してみた。
実行してみると、スレッドのほうがコンテキストスイッチは軽く、だいたい何マイクロ秒くらい違う、というような、期待どおりの結果は得られなかった。まず、データに数十分以上の周期の成分が含まれているようで、実行するたびに平均値が大きく変動してしまい、うまく比較できない。スレッドとプロセスでどちらが早いとも言えない、という感じだった。値の範囲としては、だいたい10〜30マイクロ秒くらい。
アプリケーションの外側でどんなことが起きているのかはブラックボックスだし、実際にコンテキストスイッチにかかる時間というのはこのくらい不安定なのだという可能性も否定はできないものの、いまいち腑に落ちない。APIから取得した値によると、タイマーの解像度は42ナノ秒ということになっているけれど、もしかすると、この実験が必要とするほどの精度はないのかもしれない。3
そもそもこの方法で正しくコンテキストスイッチの時間を計測できているんだろうか。 このコードで計測しているものを図にすると以下のようになる。
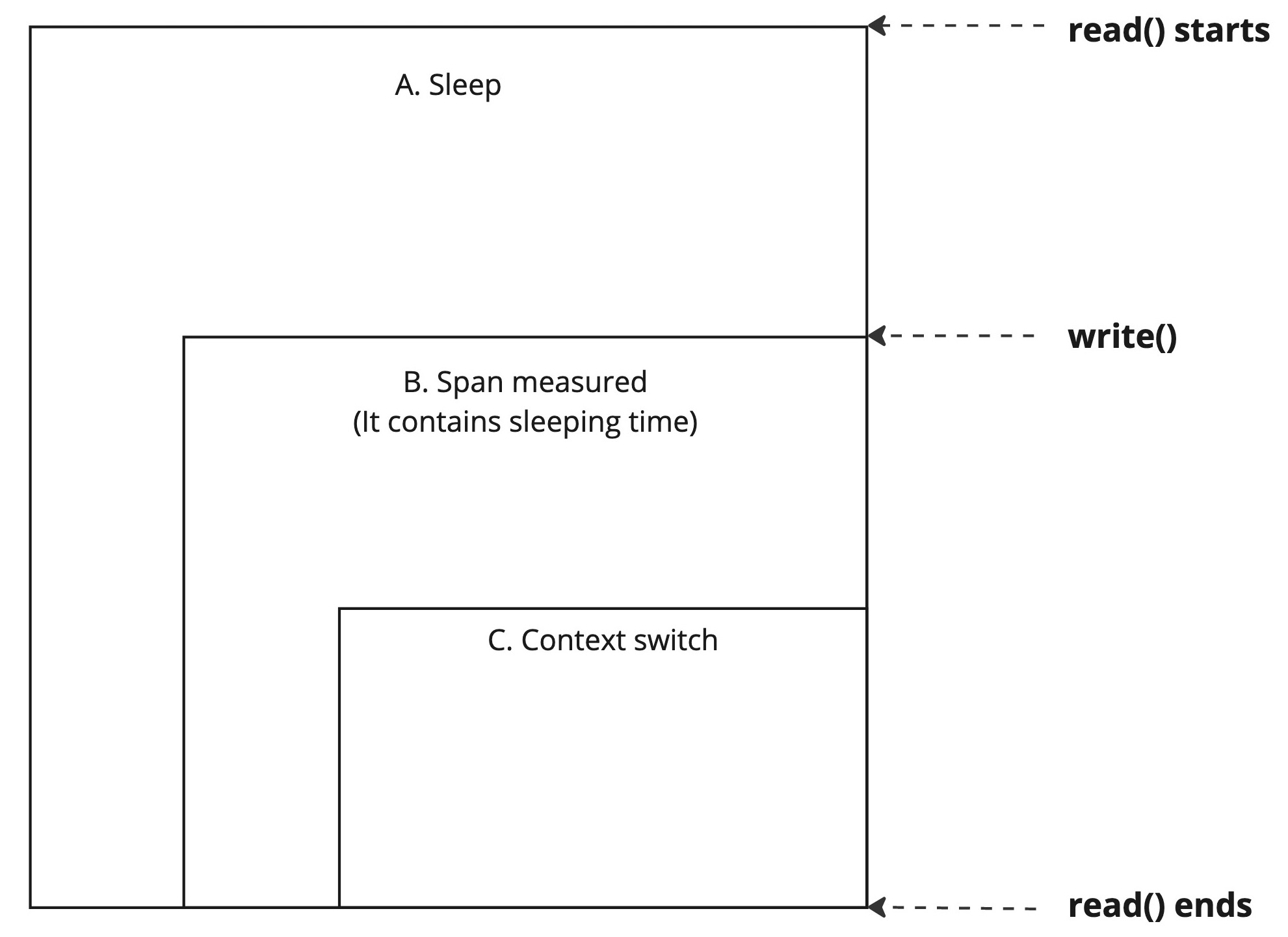
read()開始から終了までのイベント。
Aはread()がはじまって、タスクが休眠状態になってから、復帰してデータを読み込み終了するまで全体の時間。 その中には、Cのコンテキストスイッチにかかる時間も含まれる。 Bは、このコードで実際に計測している、write()の直前からread()の直後までの時間だ。 しかし、よくよく考えてみると、write()が発行されてから、即座にコンテキストスイッチが起きるという保証はなにもない。 スケジューラーが、対象のスレッドを選択するまでに、コンテキストスイッチ自体よりも長い時間がかかるとしたら、このコードでは意味のある計測をできていないことになる。
実験2: より実際的なモデル
なにかもっとうまくコンテキストスイッチのパフォーマンスを比較できる方法はないだろうか。 そもそも知りたいことは、スレッドとプロセスで、(メモリはさておき)実行時間的な意味でパフォーマンス上の差異あるのかどうかだ。スレッドのかわりにプロセスを使うことで、理論的に、パフォーマンスが低下する可能性があるのかどうかを把握しておきたい。
そこで、次のような単純な方法を考えた。 タスクとパイプを2つずつ用意し、タスク間で、整数をインクリメントしながら、ひたすら往復させる。 これで、単位時間によりたくさんメッセージを送信できたほう(整数の数が多かったほう)が勝ち、という方法。 送受信に使っているAPIや処理も同じで、異なるのはタスクの種類がプロセスかスレッドかという部分だけだ。 これで結果が異なるなら、どちらがより早くコンテキストスイッチできるのかの競争になっていると思う。 まとまった量の処理を計測するので、タイマー精度についての懸念もない。
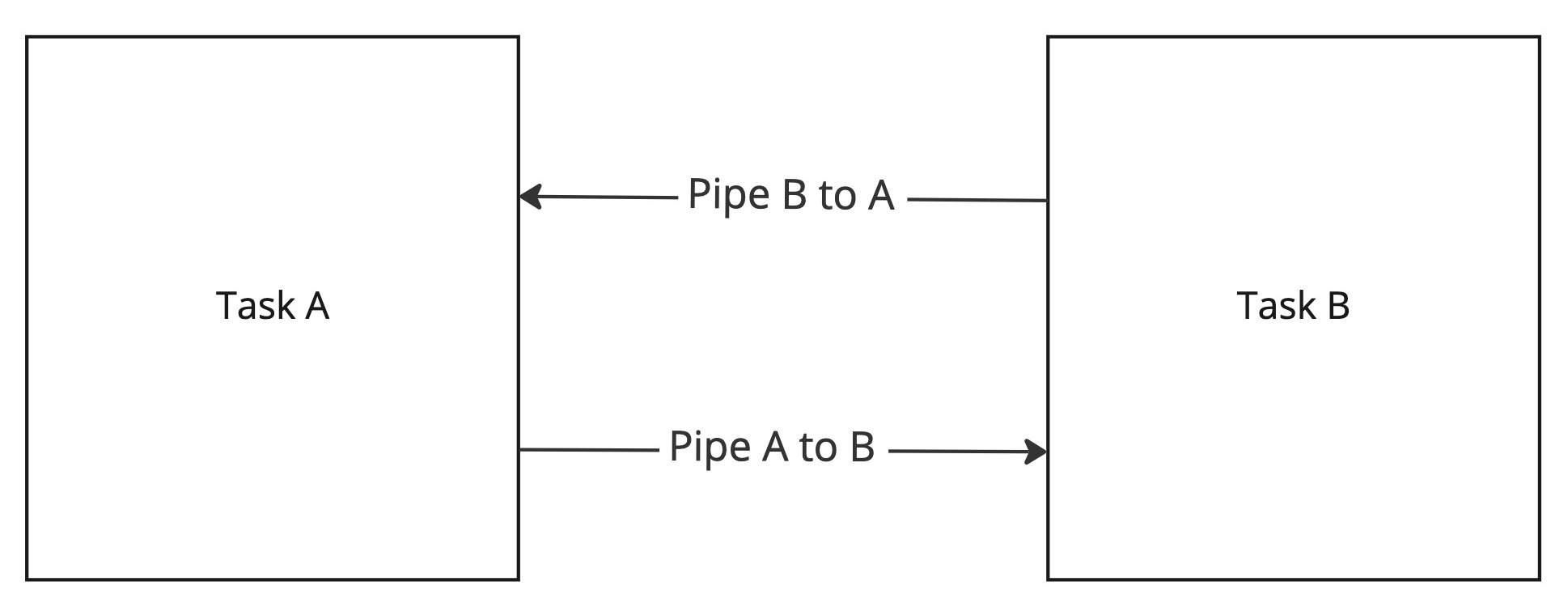
パイプを2本用意して、タスク間で送信し合う
この方法でやってみると、スレッドとプロセスで実際に差が出た。 手元のMac環境だと、スレッドは秒間40万スイッチ、プロセスは秒間36万スイッチくらいで、プロセスのほうがすこし回数がすくない。
プロセスよりも、スレッドのほうが、高速にコンテキストスイッチできることがわかった。
プロセス VS スレッド
われわれアプリケーションプログラマにとって重要なのは、アプリケーションで並行処理を設計するにあたって、スレッドとプロセスどちらのAPIを選ぶのが適切なのかということだ。
パフォーマンスという点だけを考えるとプロセスを選択する理由はなさそうにも思えるけど、設計上のすばらしいメリットがあると思っている。それは、互いがより厳密に隔離されているという点だ。メモリなどの資源についても、それぞれのプロセスレベルで管理されているので、プロセスが終了すればOSが勝手に回収してくれる。つまり、プロセスのほうが、考えることがすくなく、実装がシンプルになる。
一方で、プロセス間ではメモリ空間が共有されないため、より緊密に連携したかったり、メモリ資源を節約したかったりする場合には、スレッドが必要になる。スレッドのほうが、同期のための手段も豊富にある。
単位時間にスイッチできる回数という点で、スレッドのほうが多少有利なことが今回わかったけど、そこまで著しい差があるわけではない。だから、選択にあたって、コンテキストスイッチのコストはそこまで重視する部分ではないと思う。それよりも、他の特性を考慮して、アプリにあった手段を選ぶべきだ。
最後に、こういうケースだとコンテキストスイッチのコストが違ってくるよ、こういうツールや方法を使えば、もっとうまく測れるよなどの知恵をお持ちの方は、ぜひ教えてください。