この記事は ムラサメ研究所 学会 Advent Calendar 2018 の21日目の記事です。
現代的なOSであれば、ディスクから読み込んだデータをバッファーキャッシュ(UNIX系)あるいはファイルキャッシュ(Windows)などと呼ばれる RAM上の領域にキャッシュしておく機能があります(以降バッファーキャッシュで統一)。 したがって、同じファイルを2回以上読みこむと、2回目以降のほうが高速に読み込める見込みが高いです。1
本記事では、このことを実験的に確認し、その事実がアプリケーションプログラミングに与える影響を考察します。
バッファーキャッシュとは
バッファーキャッシュは、カーネルの管理しているメモリ空間に配置され、アプリのアクセスできるユーザー空間とは隔離されています。 これはカーネルによって透過的に管理されているため、ふだんアプリケーションプログラミングをしている分には、あまり意識することがありません。
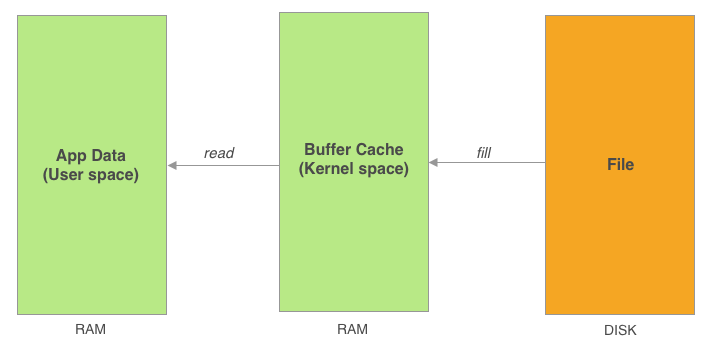
バッファーキャッシュ
アプリがファイルからデータを読み込むためにシステムコールを発行すると、まずバッファーキャッシュに該当するデータが存在するか確認されます。 キャッシュ上にデータが存在する場合、そのデータがユーザー空間にコピーされます。ディスクアクセスが発生しないため高速です。
キャッシュ上にない場合は、ディスクからデータが読み込まれ、バッファーキャッシュにデータが充填されます。 ディスクアクセスが発生するため低速ですが、次回以降の同一データへのアクセスは高速化されることが期待できます。 ちなみに、1MBのデータをメインメモリから読み込むのとディスクから読み込むのでは 10倍くらい開きがある ようです。
バッファーキャッシュの利用は、あくまでカーネル管理下で行われる裏方の処理なので、 アプリケーションから明示的にキャッシュを操作したり解放したりすることは、基本的にはできませんし、 以前アクセスしたからといって、次回アクセス時にキャッシュが残っているという保証もありません。
検証方法
どうすればバッファーキャッシュの効果を確認できるのか考えます。 基本的な考えかたとしては、ファイルからのデータ読み込み時間を計測し、初回アクセスと2回目のアクセスでは、後者のほうが速くなることを確かめれば良さそうです。バッファーキャッシュの増減やディスクアクセスなども観測できると、なお良いでしょう。
筆者が普段使っているのはmacOS(Darwin)なので、検証もmacOSで行います。CPUはCore i7 3.1GHz、RAM 16GB、SSDという環境です。 macOSでは、ファイルディスクリプタに対して、fcntlシステムコールでF_NOCACHEフラグを指定することで、 当該ファイルディスクリプタ経由でのアクセス時にキャッシュ充填をしないようにできます。
ただし、すでにバッファーキャッシュが存在する場合はそちらからデータを取ってきてしまうため、 実験のためにはキャッシュされていないことを保証する必要があります。 これにはpurgeコマンドが使えます。このコマンドを使うとバッファーキャッシュがクリアされます。
LinuxではO_DIRECTフラグ、WindowsではFILE_FLAG_NO_BUFFERINGフラグを使えば同様の挙動が実現できます。 というか、これらはキャッシュがあっても直接ディスクを読みにいくので、macOS以外のほうが実験しやすいかもしれません。
ディスクアクセスは、OS付属のfs_usageコマンドで確認できます。 バッファーキャッシュの量は、確認する方法がわかりませんでした。
検証用プログラム
検証用に以下のスクリプトを作成しました。 ファイルを繰り返し読み込み、読み込みにかかった時間を計測するプログラムです。
# read_file_test.py
import fcntl
import json
import time
import argparse
class measure_time():
def __init__(self, label = ''):
self.label = label
def __enter__(self):
self.t0 = time.time()
def __exit__(self, type, value, traceback):
t1 = time.time()
print('{}: {:.6f}'.format(self.label, t1 - self.t0))
def read(static, no_cache, parse):
with open(static, 'rb') as f:
if no_cache:
fcntl.fcntl(f.fileno(), fcntl.F_NOCACHE, 1)
data = f.read()
if parse:
json.loads(data)
def parse_args():
parser = argparse.ArgumentParser(description='File read test')
parser.add_argument('input', nargs='?', help='file to read')
parser.add_argument('-c', '--count', type=int, help='number of repetition', default=100)
parser.add_argument('-n', '--no-cache', dest='no_cache', action='store_true')
parser.add_argument('-s', '--sleep', type=int, help='sleep time')
parser.add_argument('-p', '--parse', action='store_true', help='parse data as json')
return parser.parse_args()
def main():
args = parse_args()
with measure_time('total'):
for i in range(args.count):
with measure_time(i):
read(args.input, args.no_cache, args.parse)
if args.sleep:
time.sleep(args.sleep)
if __name__ == '__main__':
main()
読み込み回数、F_NOCACHEフラグの有無、繰り返し毎のsleepなどが指定できます。 また、実際のプログラムでは読み込んだデータに対してなんらかの処理をするはずなので、 典型的なタスクとして、読み込んだデータをJSONとしてパースすることもできます。
検証結果
まずは、1MiBのデータを作成します。
$ dd if=/dev/random of=1MB_data count=1024 bs=1024
キャッシュOFFで100回,1MBのデータを読み込んでみます。 最初にpurgeコマンドを実行してキャッシュクリアしていることに注意してください。
$ sudo purge && python3 read_file_test.py 1MB_data --count=100 --no-cache
中略
97: 0.001974
98: 0.002611
99: 0.001890
total: 0.186595
1回の読み込みに平均1.87ミリ秒程度かかりました。
今度はキャッシュONで読み込んでみます。 まずは一回読み込んでキャッシュを充填させます。
$ python3 read_file_test.py 1MB_data --count=1
この状態で実行すれば、ディスクアクセスは発生しないはずです。
$ python3 read_file_test.py 1MB_data --count=100
中略
97: 0.000339
98: 0.000557
99: 0.000364
total: 0.025158
平均は0.25ミリ秒程度まで縮まりました。
キャッシュなしだと、数倍〜十数倍程度は遅くなるようです。 おおむね期待通りの結果になりました。
次は、キャッシュON/OFFで実際にディスクアクセスパターンが変化しているのか確認します。 ディスクアクセスをリアルタイムに監視するために1秒のsleepを入れて、キャッシュOFFでスクリプトを実行します。
$ python3 read_file_test.py 1MB_data --sleep=1 --no-cache
実行中にfs_usageコマンドを使うことでディスク読み込みが発生しているか確認します。
$ sudo fs_usage -f diskio `pgrep -f read_file_test.py`
Password:
23:19:05 RdData[AN] 1MB_data 0.001928 W Python
23:19:06 RdData[AN] 1MB_data 0.002141 W Python
23:19:07 RdData[AN] 1MB_data 0.002193 W Python
23:19:08 RdData[AN] 1MB_data 0.002167 W Python
23:19:09 RdData[AN] 1MB_data 0.002226 W Python
23:19:10 RdData[AN] 1MB_data 0.001808 W Python
23:19:11 RdData[AN] 1MB_data 0.002109 W Python
23:19:12 RdData[AN] 1MB_data 0.002303 W Python
23:19:13 RdData[AN] 1MB_data 0.001472 W Python
23:19:14 RdData[AN] 1MB_data 0.001120 W Python
23:19:15 RdData[AN] 1MB_data 0.002314 W Python
^C
たしかに、1秒ごとにディスク読み込みが発生が発生しています。 今度は、キャッシュONで実行してみると、
$ sudo purge && python3 read_file_test.py 1MB_data --sleep=1
同様にfs_usageで確認します。
$ sudo fs_usage -f diskio `pgrep -f read_file_test.py`
^C
出力がなにもありません。 キャッシュONのときには、たしかにディスクアクセスが発生していません。 なお、バッファーキャッシュの増減もvm_statコマンドなどで監視できそうな気がしたのですが、 結果をどう解釈して良いかわからなかったので省略します。
では、読み込むファイルサイズを変えると、結果は変わるでしょうか? 次はこの疑問を確かめてみましょう。
さきほど作成した1MiBに加えて、1KiB,1GiBのデータを作成します。
$ dd if=/dev/random of=1KB_data count=1 bs=1024
$ dd if=/dev/random of=1GB_data count=1048576 bs=1024
1KiBキャッシュあり
$ python3 read_file_test.py 1KB_data --count=1 && python3 read_file_test.py 1KB_data --count=100
中略
total: 0.008201
1KiBキャッシュなし
$ sudo purge && python3 read_file_test.py 1KB_data --count=100 --no-cache
中略
total: 0.025077
1MiBキャッシュあり
$ python3 read_file_test.py 1MB_data --count=1 && python3 read_file_test.py 1MB_data --count=100
中略
total: 0.023998
1MiBキャッシュなし
$ sudo purge && python3 read_file_test.py 1MB_data --count=100 --no-cache
中略
total: 0.174918
1GiBキャッシュあり
$ python3 read_file_test.py 1GB_data --count=1 && python3 read_file_test.py 1GB_data --count=100
中略
total: 72.426231
1GiBキャッシュなし
$ sudo purge && python3 read_file_test.py 1GB_data --count=100 --no-cache
中略
total: 78.807513
1回の平均読み込み時間(ミリ秒)
| キャッシュあり | キャッシュなし | |
|---|---|---|
| 1KiB | 0.08 | 0.25 |
| 1MiB | 0.24 | 1.75 |
| 1GiB | 724.26 | 788.08 |
1GiBのときのみ、キャッシュなしにも関わらず、2回目以降の読み込みが速くなるという不思議な現象が見られました。 また、1GiBになると、若干の速度向上は見られるものの、それまで見られていた数倍レベルの速度向上が見られなくなりました。 この速度低下がなにに起因するものなのか、筆者には確認する方法が思い付きません。 ちなみに、1GiBの場合でもディスクからの読み込み自体は発生していません。 全データキャッシュに乗ってはいるようです。
アプリケーションプログラミングへの影響
ここまでで確認できた、バッファーキャッシュによって2回目以降のファイル読み込みが高速化されるという事実は、 アプリケーションプログラミングにたいして何か影響を及ぼし得るでしょうか?
ひとつのアプリ内において、コード的に離れた部分で、同一のファイルに対して何度も処理を行うケースが考えられます。 同一のファイルを何度もオープンして読み込むのは無駄が多いような気がしますし、 全体の処理速度がそのために遅くなりはしないか、不安な気持ちが湧くかもしれません。
何度も読み込むよりは、読み込んだデータをアプリのメモリ内にキャッシュしておいて、再利用したくなってきます。 ですが、このようなキャッシュ処理を追加すると余分なコードが発生し、すこしコードが汚れてしまうかもしれません。 逐次必要に応じてファイルを読み込む設計ならば、対象のファイル名だけが各部に行き渡っていれば十分です。
このような迷いが生じたときに、OSのバッファーキャッシュにキャッシュを任せることによって、 アプリのコードをシンプルに保つ望みが持てるかもしれません。
ところで、このようなシチュエーションでは、ファイルを読み込むだけではなく、 実際に読み込んだデータに対してなんらかの処理を加えるはずです。 ですから、単にファイル読み込みの時間を計測するだけなく、データ処理の時間も合わせて測らなければ片手落ちです。 ここでは、よくある処理の例として、読み込んだデータをJSONとしてパースしてみます。 2
比較用に、純粋にJSONパースの時間だけを計測するためのスクリプトも作成しました。
# parse_json_test.py
import json
import time
import argparse
class measure_time():
def __init__(self, label = ''):
self.label = label
def __enter__(self):
self.t0 = time.time()
def __exit__(self, type, value, traceback):
t1 = time.time()
print('{}: {:.6f}'.format(self.label, t1 - self.t0))
def parse_json(data):
json.loads(data)
def parse_args():
parser = argparse.ArgumentParser(description='JSON parse test')
parser.add_argument('input', nargs='?', help='file to read')
parser.add_argument('-c', '--count', type=int, help='number of repetition', default=100)
return parser.parse_args()
def main():
args = parse_args()
with open(args.input, 'rb') as f, measure_time('total'):
data = f.read()
for i in range(args.count):
with measure_time(i):
parse_json(data)
if __name__ == '__main__':
main()
JSONデータは、 JSON Generator というサイトで生成した 145KiB程度のデータ です。
パースあり、キャッシュあり
$ python3 read_file_test.py sample.json --count=1 && python3 read_file_test.py sample.json --count=100 --parse
中略
total: 0.159036
パースなし、キャッシュあり
$ python3 read_file_test.py sample.json --count=1 && python3 read_file_test.py sample.json --count=100
中略
total: 0.007628
パースあり、キャッシュなし
sudo purge && python3 read_file_test.py sample.json --count=100 --parse --no-cache
中略
total: 0.248836
パースなし、キャッシュなし
sudo purge && python3 read_file_test.py sample.json --count=100 --no-cache
中略
total: 0.053962
パースのみ(データ読み込みなし)
$ python3 parse_json_test.py sample.json --count=100
中略
total: 0.151621
1回の平均処理時間(ミリ秒)
| パースあり | パースなし | |
|---|---|---|
| キャッシュあり | 1.59 | 0.08 |
| キャッシュなし | 2.49 | 0.54 |
| データ読み込みなし | 1.52 |
この結果からわかるのは、実際のデータ処理に比べれば、ファイルの読み込み時間は比較的割り合いが小さい、ということです。 ファイル読み込み時間の占める比率が小さいのであれば、そもそもキャッシュがどうこうを気にする意味すらありません。 ただ、この計測結果はPythonで行ったもので、CやC++でJSONのパースを行えば簡単に10倍くらいは差が付くため、 C/C++アプリではファイル読み込みの締める比重が大きくなり、バッファーキャッシュの重要性が相対的に増すということは、十分に考えられます。
まとめ
OSのバッファーキャッシュが有効に働くため、1MiB程度のファイル読み込みならば高速化されることが確認できました。 1GiBだとなぜか高速化されませんでしたが、これは原因がよくわかりません。 また、純粋なデータ読み込みよりもJSONパースのほうがはるかに時間がかかることもわかりました。
したがって、アプリケーションプログラミングにおいて、純粋なファイル読み込みの時間というのは、あまり気にしないで良さそうです。
参考リンク
- Performance Tools macOS付属のパフォーマンス計測用ツール集
- OSX fcntl(fd, F_NOCACHE, 1) not equivalent to O_DIRECT on Linux #48 F_NOCACHEの挙動(キャッシュがあると見にいっちゃう)について
- Purge the OS X disk cache to analyze memory usage purgeコマンドの解説
- Numbers Everyone Should Know ディスクアクセスやメモリアクセスなど各種速度まとめ
- The fastest JSON parser in the world? 各種言語でのJSONパースベンチマーク
- File Caching Windowsのファイルキャッシュについて
- Chapter 6. Memory Management Linux仮想メモリの概要